The latency when retrieving data from the L1 cache is two hundredth of the latency when retrieving data from main memory. Every programmer should know the latency to get data from typical equipments like L1 cache, main memory, SSD disk, the internet network or etc.
I would like to share latency comparison numbers from an awesome article Latency Numbers Every Programmer Should Know.
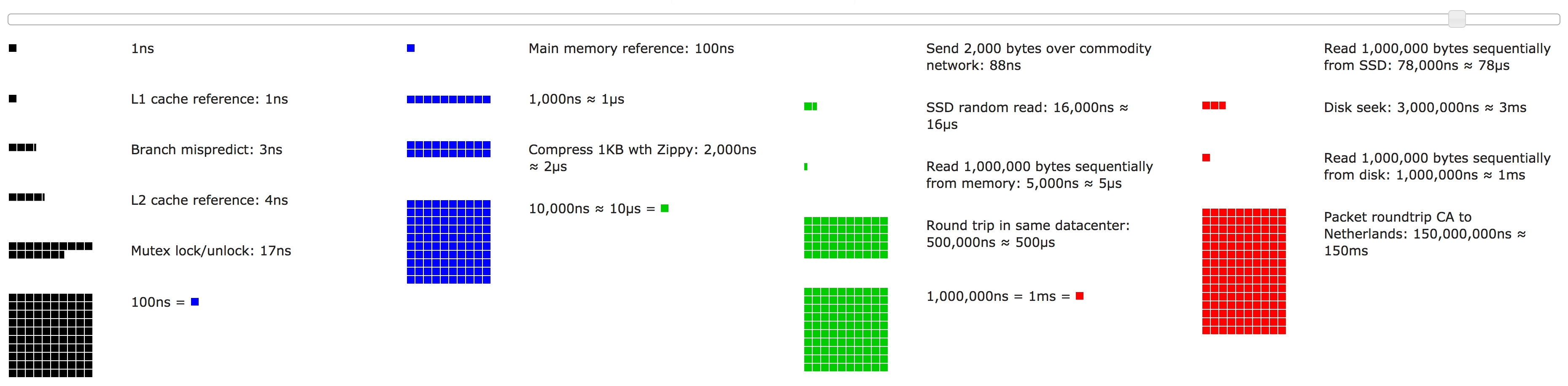
🐝 Latency Comparison Numbers
| Equipment | Letency(10^-9) | Latency(10^-6) | Latency(10^-3) |
|---|---|---|---|
| L1 cache reference | 0.5 ns | ||
| Branch mispredict | 5 ns | ||
| L2 cache reference | 7 ns | ||
| Mutex lock/unlock | 25 ns | ||
| Main memory reference | 100 ns | ||
| Compress 1K bytes with Zippy | 3,000 ns | 3 us | |
| Send 1K bytes over 1 Gbps network | 10,000 ns | 10 us | |
| Read 4K randomly from SSD* | 150,000 ns | 150 us | |
| Read 1 MB sequentally from memory | 250,000 ns | 250 us | |
| Round trip(as the ping time) within same datacenter | 500,000 ns | 500 us | |
| Reat 1 MB sequentially from SSD* | 1,000,000 ns | 1,000 us | 1 ms |
| Disk seek | 10,000,000 ns | 10,000 us | 10 ms |
| Read 1 MB sequentially from disk | 20,000,000 ns | 20,000 us | 20 ms |
| Send packet CA -> Netherlands -> CA | 150,000,000 ns | 150,000 us | 150 ms |
In the site shows the image of these outlines by color blocks:
🎃 Reference
L1, L2 cache
L1 and L2 are levels of cache memory in a computer. If the computer processor can find the data it needs for its next operation in cache memory, it will save time compared to having to get it from random access memory. L1 is “level-1” cahce memory, usually build onto the microprocessor chip itsefl. For example, the Intel MMX microprocessor comes with 32 thousand bytes of L1.
L2 (that is, level-2) cache memory is on a separate chip (possibly on an expansion card) that can be accessed more quickly than the large “main” memory. A popular L2 cache memory size is 1 MB.
http://whatis.techtarget.com/definition/L1-and-L2
Branch predictor
In computer architecture, a branch predictor is digital circuit that tries to guess which way a branc will go before this know definively. The purpose of the branch predictor is to improve the flow in the instruction piplline. Branch predictor play a critical role in achieving high effective performance in many modern pipelined microprocessor architecture such as x86.
The time that is wasted in case a branch mispredition is equal to the number of stages in the pipeline from the fetch stage to the execute stage. Modern microprocessors tend to have quite long pipeline so that the misprediction delay is between 10 and 20 clock cycles.
https://en.wikipedia.org/wiki/Branch_predictor
Mutex lock
In computer science, a lock or mutex is a synchronization mechanism for enforcing limits on access to a resource in an environment where there are many threads of execution. A lock is designed to enforce a mutual execution concurrency control policy.
https://en.wikipedia.org/wiki/Lock_(computer_science)
The calling thread locks the
mutex, blocking if necessary:
- If the mutex isn’t currently locked by any thread, the calling thread locks it (from this point, and until its member
unlockis called, the thread owns themutex)- If the
mutexis currently locked by another thread, execution of the calling thread is blocked untilunlockedby the other thread (other non-locked threads continue their execution)- If the
mutexis currently locked by the same thread calling this function, it produces adeadlock( with undefined behavior).
All
lockandunlockoperations on themutexfollow a single total order, with all visible effects synchronized between the lock operations and previous unlock operations on the same object.
http://www.cplusplus.com/reference/mutex/mutex/lock/
Round-trip delay time
In the context of computer networks, the signal is generally a data packet, and the round-trip time(RTT) is also known as the ping time. An internet user can determine the RTT by using the ping command.
https://en.wikipedia.org/wiki/Round-trip_delay_time
Seek Time (HDD)
Seek time is a measure of how long it takes the hard assemly to travel to the track of the disk that conatins data.
https://en.wikipedia.org/wiki/Hard_disk_drive
🖥 Recommended VPS Service
VULTR provides high performance cloud compute environment for you.
Vultr has 15 data-centers strategically placed around the globe, you can use a VPS with 512 MB memory for just $ 2.5 / month ($ 0.004 / hour).
In addition, Vultr is up to 4 times faster than the competition, so please check it => Check Benchmark Results!!
